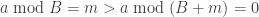In today’s techtalk in Pivotal Inc. one of my colleagues asked a question about the benefits of double the batch size of one step in a hashjoin algorithm. I think it is not obvious enough to understand it at first glimpse. So I offer the formal description and proof here to make sure that myself understand it well.
The problem in informal language
We have a hash function 




At some point, we find that the number of numbers in the batch is larger than 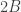
The lemma in formal language
The problem above can be represented in formal language as follows:
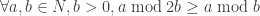
Let’s prove this lemma:

let 
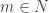
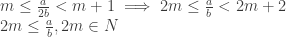
Now, according to concrete mathematics Page 69’s (3.7), we have

Proof end.
Other enlarging strategies?
If we just increase the batch size by 

The answer is no. To disprove it, all we need to do is to offer a bad case: